
手把手带你 5 分钟构建以图搜图系统#
向量和向量数据库#
向量在数学中是一个可以表示多个维度或特性的对象。在我们日常生活中,也可以用来描述一个物体的多个属性。
比如,我们要描述一个苹果,需要关注它的特征(如品种)、产地、颜色、大小和甜度等属性。我们可以把这些属性看作是苹果的多个维度,然后用一个向量来表示这个苹果。
例如,设定向量的每一个元素分别代表:
- 特征(如,1 代表红富士苹果,2 代表国光苹果)
- 产地(如,1 代表洛川,2 代表烟台)
- 颜色(如,1 代表红色,2 代表绿色)
- 大小(以实际重量为准,如,150 代表苹果重 150 克,200 代表苹果重 200 克)
- 甜度(如,1 代表非常甜,0.5 代表一般,0 代表不甜)
那么一个红富士苹果,产地在烟台,颜色为红色,重量为 150 克,甜度为 0.8 的向量就可以表示为 [1, 2, 1, 150, 0.8]。通过这个向量,我们就可以全面地描述这个苹果的所有属性。
这就是向量的概念。在人工智能和机器学习中,我们可以将音频、图像、复杂的文本向量化后存储。传统的数据库主要是为处理结构化数据设计的,然而,对于复杂的数据类型,传统的数据库处理起来效率低下。
相比之下,向量数据库支持多种索引类型和相似性计算方法,且能够高效地存储和查询大规模的向量数据。
向量数据库的应用#
假设有一天,你在一家餐厅吃到了一道非常美味的菜,但你并不知道它的名字或如何制作。你可以拍下这道菜的照片,然后通过以图搜图的功能,在线搜索类似的菜品和对应的菜谱。
假设一个在线菜谱平台,存储了大量的菜品图片和对应的菜谱。每一张菜品图片都经过特征提取,生成了相应的嵌入向量,并存储在向量数据库中。
当用户上传一张菜品照片进行搜索时,平台会先对这张照片进行同样的特征提取,生成一个嵌入向量,然后在向量数据库中搜索与之最相似的菜品图片。
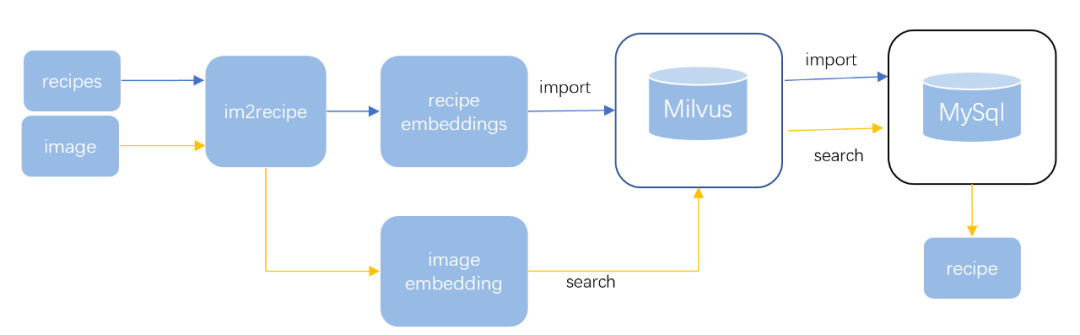
搜索结果会返回一系列相似的菜品图片以及它们对应的菜谱。用户可以浏览这些菜谱,找到他们想要的菜品,学习如何制作这道菜。
这种以图搜图的功能不仅可以帮助用户找到他们喜欢的菜谱,还可以帮助他们发现新的、可能会喜欢的菜品。这对于菜谱平台来说,也是一种吸引用户、增加用户粘性的有效方式。
此外,以图搜图的技术在生活中还有许多实际应用案例,如:购物推荐类似商品、公安对监控视频中的人脸进行识别,提高破案效率。
以上这些都离不开一个高性能的向量数据库。在本文中,我们将搭建一套以图搜图的系统,来亲自体验整个工作流程。
腾讯云向量数据库#
腾讯云向量数据库提供了强大的存储、检索、分析大量多维向量数据的能力,可支持 10 亿级单索引向量规模、百万级 QPS 及毫秒级查询延迟。目前已稳定服务上千家客户,我们可以在分钟内创建一个向量数据库实例。
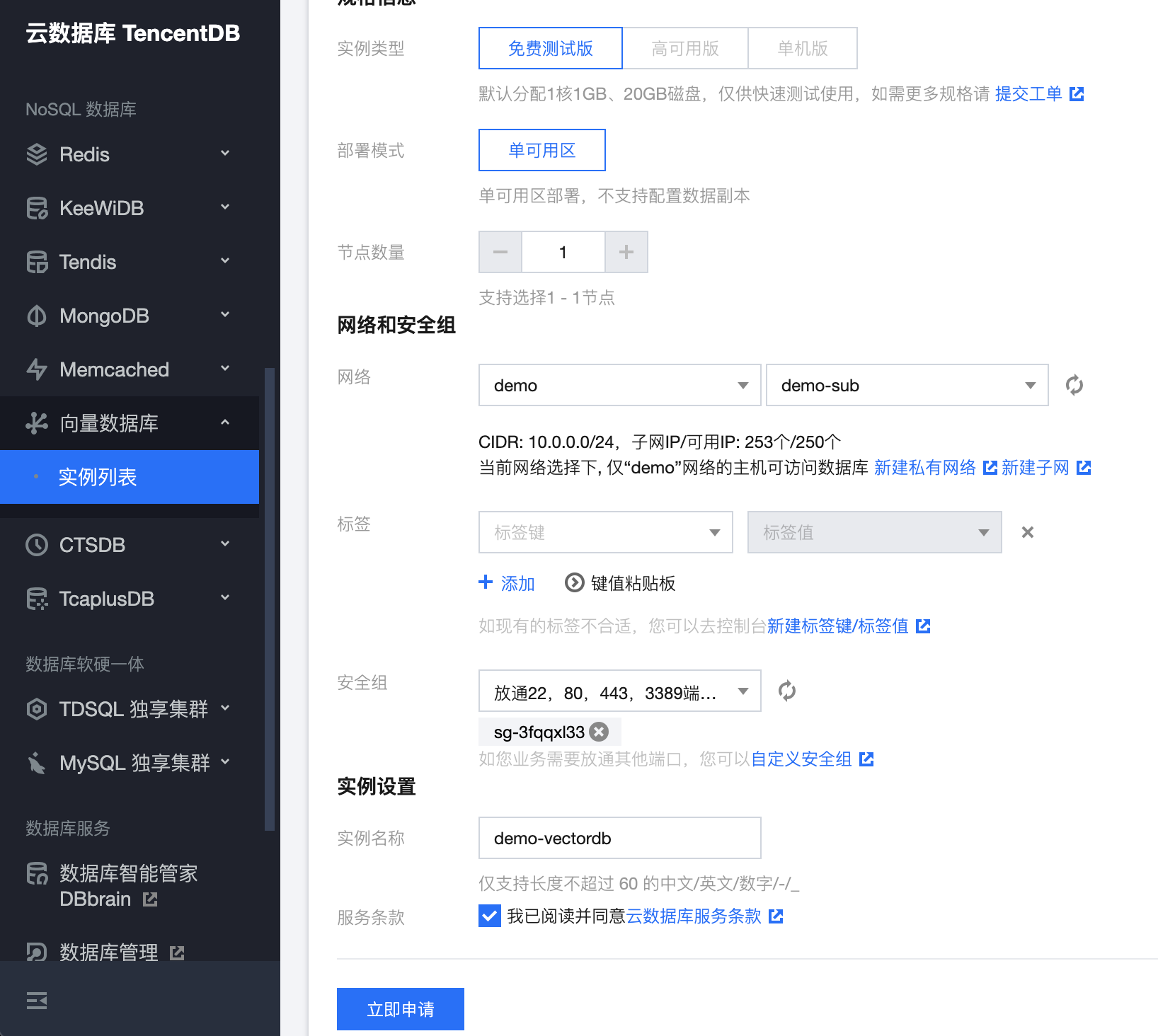
测试版:单可用区、单节点。
整个创建过程大概需要 1-2 分钟,刷新实例列表,即可看到创建好的实例。

在密钥管理中获取用户名 root 的密码,下面会用到:

开启外网访问:可以使用系统分配的域名和端口通过外网访问向量数据库:
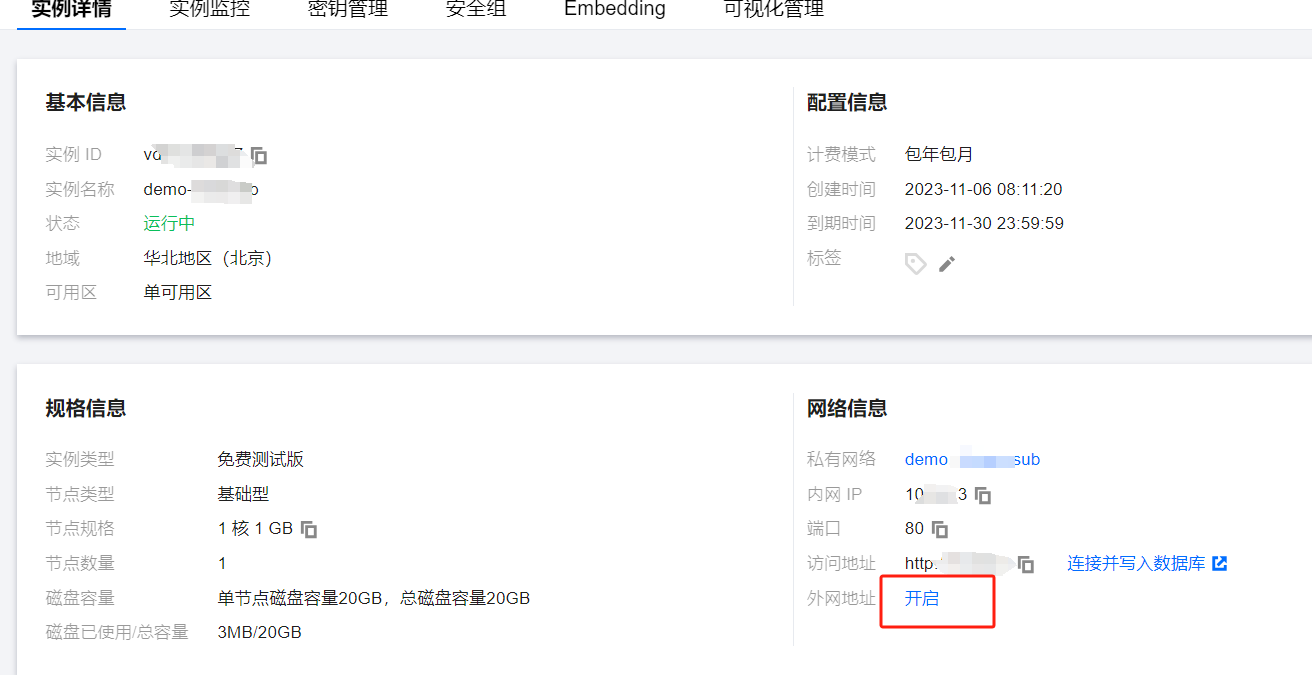
生效时间大概在 10s 内,请记住这里生成的 域名(HOST) 和 端口(PORT)
配置白名单:如果出于测试目的,白名单 IP 段可以设置为 0.0.0.0/0 意味着对所有 IP 开放。
配置白名单后,可以用下面命令测试外网连通性:
curl -i -X POST \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer account=root&api_key=A5VOgsMpGWJhUI0WmUbY********************' \
http://10.0.X.X:80/database/create \
-d '{
"database": "db-test"
}'
返回结果如下。如果连不上,或者超时,则是白名单配置不正确。
{"code":0,"msg":"operation success","affectedCount":1}
以图搜图案例#
下面我们使用 Towhee 和 腾讯云向量数据库构建一个以图搜图(Reverse Image Search)系统。
Towhee 是一个用于构建强大的数据流水线的开源框架,它可以有效地处理各种数据转换任务。
该系统以图片作为输入,基于图片的内容检索出最相似的图片。其背后的基本思想是利用预训练的深度学习模型提取出每个图片的特征,并将其表示为一个嵌入向量(Embedding)。然后,通过存储和比较这些图片嵌入向量,实现图片的检索。
工作流程如下:
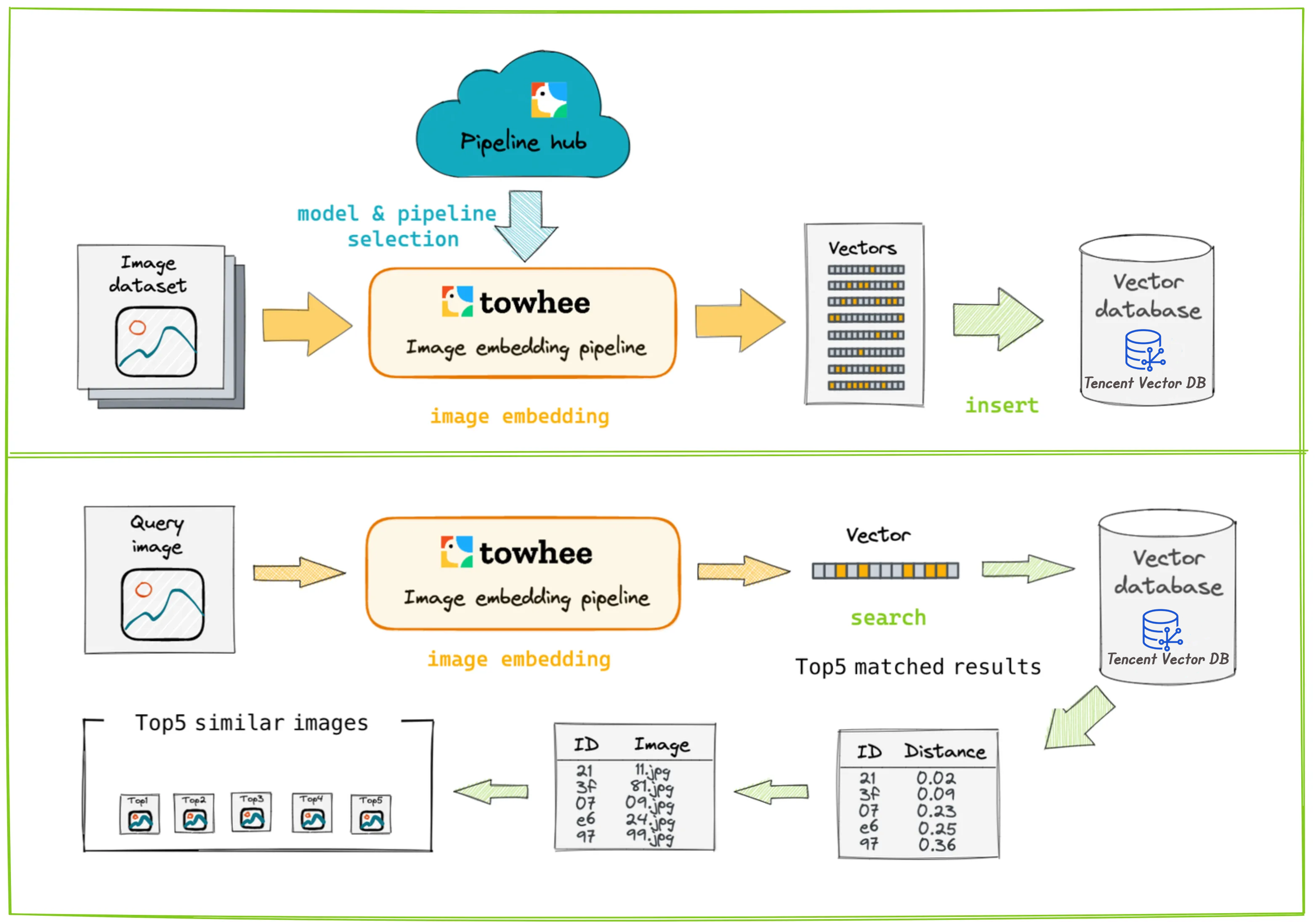
首先,使用 Towhee 对输入图片进行预处理并提取特征,得到图片的嵌入向量。然后,将这个嵌入向量存入向量数据库中。当需要检索图片时,同样先对查询图片进行预处理和特征提取,得到查询图片的嵌入向量。在向量数据库中对该向量进行相似性检索,向量数据库会返回与该向量相似的 top k 个向量。
构建项目#
下面会对重要的代码部分做详解,最终的 demo 代码,可以在文末获取,代码拉到本地就可以运行,对新手很友好
- 创建一个新的项目目录:
mkdir -p image-search
cd image-search
- 创建一个新的 Python 虚拟环境(可选,但推荐):
$ python -V
Python 3.9.0
$ python -m venv venv
创建一个新的 Python 虚拟环境能有效地隔离项目依赖,简化依赖管理
激活这个虚拟环境:
- Linux/macOS:
source venv/bin/activate
- Windows:
.\venv\Scripts\activate
- 安装需要的 Python 包:
python -m pip install -q towhee opencv-python pillow tcvectordb
这个命令会将 Towhee,OpenCV、Pillow、tcvectordb 库安装到上面创建的虚拟目录 venv 中。
准备数据#
这里我们使用了 ImageNet 数据集的一个子集(100 个类别)。示例数据可在 Github 上获取。
curl -L https://github.com/towhee-io/examples/releases/download/data/reverse_image_search.zip -O
unzip -q -o reverse_image_search.zip
ImageNet 数据集是深度学习领域中广泛使用的大规模视觉数据集,用于图片分类和物体检测任务。在本文中,所使用的数据集是 ImageNet 的一个子集,这个子集为模型训练和验证提供了适当规模和复杂度的数据。
目录结构如下:
train:包含候选图片的目录,有 100 个不同的类别,每个类别包含 10 张图片test:包含查询图片的目录,与训练集同样的 100 个类别,但每个类别只有 1 张图片reverse_image_search.csv:一个 csv 文件,包含每个训练集图片的 id、路径和标签
候选图片是指可能会被检索的图片,查询图片是指用于检索的图片。
连接数据库并新建 Collection#
连接 Tencent Vector DB 很简单,官方提供了多种语言的 SDK,本文使用 Python SDK: tcvectordb 操作向量数据库。
首先利用 tcvectordb sdk 编写连接向量数据库的客户端代码:
class TcvdbClient(PyOperator):
def __init__(self, host: str, port: str, username: str, key: str, dbName: str, collectionName: str,
timeout: int = 20):
"""
初始化客户端
"""
# 创建客户端时可以指定 read_consistency,后续调用 sdk 接口的 read_consistency 将延用该值
self.collectionName = collectionName
self.db_name = dbName
self._client = tcvectordb.VectorDBClient(url="http://" + host + ":" + port, username=username, key=key,
read_consistency=ReadConsistency.EVENTUAL_CONSISTENCY, timeout=timeout)
然后调用 TcvdbClient 构建客户端 :
# tcvdb parameters
HOST = 'lb-xxxx.clb.ap-beijing.tencentclb.com'
PORT = '10000'
DB_NAME = 'image-search'
COLLECTION_NAME = 'reverse_image_search'
PASSWORD = 'xxxx'
USERNAME = 'root'
# path to csv (column_1 indicates image path) OR a pattern of image paths
INSERT_SRC = 'reverse_image_search.csv'
test_vdb = TcvdbClient(host=HOST, port=PORT, key='6qlvBkF0xAgZoN7VJbcwLCqrxoSS4J63Q7mu4RgF', username='root',
collectionName=COLLECTION_NAME, dbName=DB_NAME)
上面的 HOST 和 PORT、USERNAME 和 PASSWORD 是申请向量数据库后获取到的。
在向量数据库中创建 DB 和 Collection:
class TcvdbClient(PyOperator):
def create_db_and_collection(self):
database = self.db_name
coll_embedding_name = self.collectionName
coll_alias = self.collectionName + "-alias"
# 创建 DB
db = self._client.create_database(database)
# 构建 Collection
index = Index()
index.add(VectorIndex('vector', 2048, IndexType.HNSW, MetricType.COSINE, HNSWParams(m=16, efconstruction=200)))
index.add(FilterIndex('id', FieldType.String, IndexType.PRIMARY_KEY))
index.add(FilterIndex('path', FieldType.String, IndexType.FILTER))
# 创建 Collection
db.create_collection(
name=coll_embedding_name,
shard=3,
replicas=0,
description='image embedding collection',
index=index,
embedding=None,
timeout=20
)
test_vdb.create_db_and_collection()
上面代码创建一个 Collection,并在这个 Collection 中添加了三个索引。在向量数据库中,Collection 是用来存储和检索向量的主要结构,创建索引的字段在检索时可以用作过滤(filter)。
vector:索引有2048向量维度。维度越高,向量可以表达的信息越多,但同时计算复杂度也越高,存储需求也越大。IndexType.HNSW索引的类型。这是一种近似最近邻搜索算法,用来加速高维向量的搜索。MetricType.COSINE是余弦相似度,它可以衡量两个向量之间的角度,通常用于衡量高维向量的相似性。id是主键索引,用来唯一标识每个向量。path是过滤索引,用来加速基于path字段的查询。
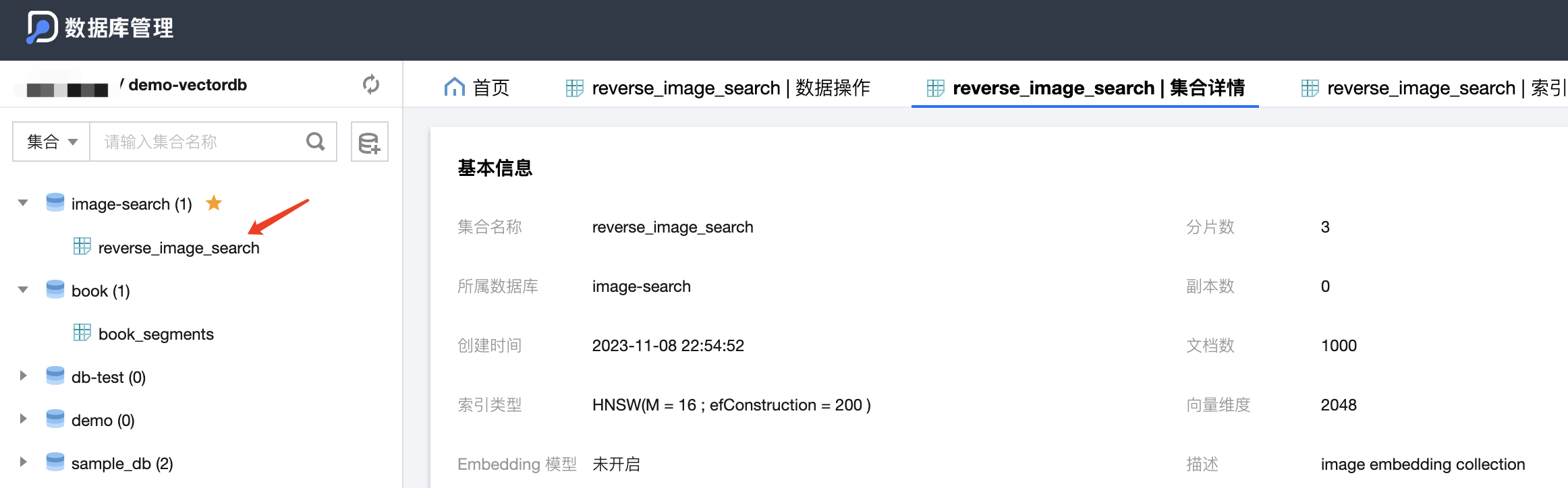
新建之后,可以通过 DMC(数据库管理)方便的查看、管理向量数据库的数据:
DMC 访问入口:https://dms.cloud.tencent.com/
下面是刚刚创建的 DB 和集合:
Embedding:图片转向量、入库#
在机器学习领域中,把文本、图片,音频等其他类型原始输入数据转换为一种更适合机器学习的形式,即将复杂的数据结构(如图片、文本等)转换为固定长度的向量的过程成为 Embedding。
下面利用 Towhee 的 pipeline 实现图片的特征提取和向量的存储:
MODEL = 'resnet50'
DEVICE = None # if None, use default device (cuda is enabled if available)
INSERT_SRC = 'reverse_image_search.csv'
# Embedding pipeline
p_embed = (
pipe.input('src')
.flat_map('src', 'img_path', load_image)
.map('img_path', 'img', ops.image_decode())
.map('img', 'vec', ops.image_embedding.timm(model_name=MODEL, device=DEVICE))
)
# Display embedding result, no need for implementation
p_display = p_embed.output('img_path', 'img', 'vec')
DataCollection(p_display('./test/goldfish/*.JPEG')).show()
# Insert pipeline
p_insert = (
p_embed.map(('img_path', 'vec'), 'mr', ops.local.tcvdb_client(
host=HOST, port=PORT, key=PASSWORD, username=USERNAME,
collectionName=COLLECTION_NAME, dbName=DB_NAME
))
.output('mr')
)
# Insert data
p_insert(INSERT_SRC)
Embedding Pipeline 定义了一个 p_embed 的管道,这个管道将 reverse_image_search.csv 中的图片加载后,调用 ops.image_embedding.timm(),使用 resnet50 模型将图片数据转换为嵌入向量。
Towhee 提供了预训练的 ResNet50 模型,可以将图片转换为向量。ResNet50 是一种深度卷积神经网络,它在许多图像识别任务中表现出色。此模型通过学习图片的重要特征,并将这些特征嵌入到一个高维向量中,称为嵌入向量(embedding vector)。
Display Pipeline 代码定义了 p_display 的管道,这个管道用于显示 p_embed 的结果。
Insert Pipeline 代码定义了 p_insert 的管道,这个管道用于将嵌入向量插入到向量数据库中。
p_insert(INSERT_SRC) 使用 p_insert 管道对 reverse_image_search.csv 文件中的图片数据进行处理。
最终会将生成的向量调用 ops.local.search_tcvdb_client,插入到向量数据库中:
def __call__(self, *data):
path = ""
vector = []
for item in data:
if isinstance(item, np.ndarray):
# Convert ndarray to list and float32 to float
vector = list(map(float, item))
else:
path = item
# Generate a random UUID and convert to string
document_list = [
Document(
id=str(uuid.uuid4()),
path=path,
vector=vector),
]
db = self._client.database(self.db_name)
coll = db.collection(self.collectionName)
coll.upsert(documents=document_list)
可以在 DMC 中,用刚刚创建了索引的字段进行过滤,精确查询到入库后的数据,例如搜索:path="./train/goldfish/n01443537_1903.JPEG" :
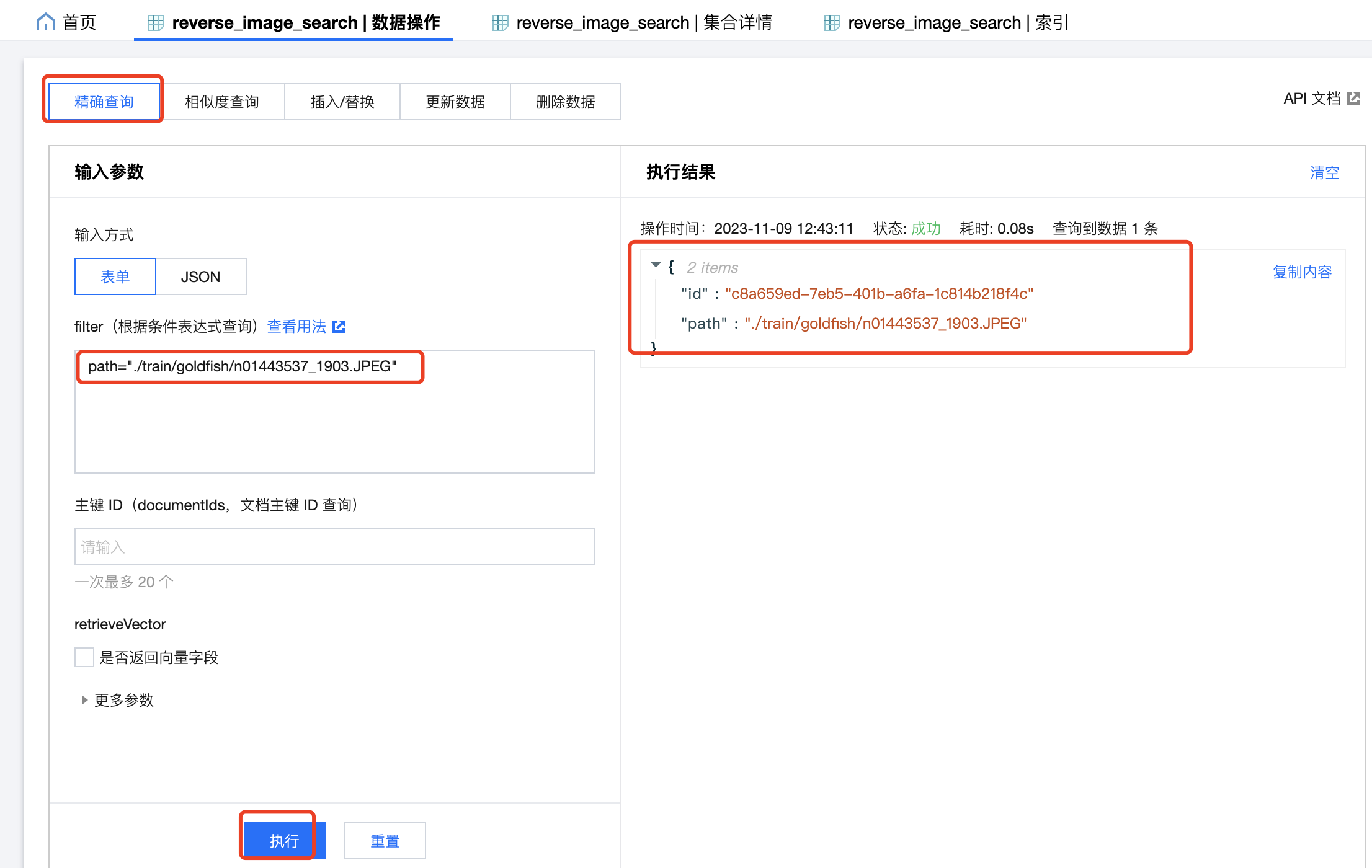
由于向量数据一般很大,默认不会返回。如果要返回向量字段需要勾选retrieveVector。
搜索相似图#
定义一个搜索管道 p_search,用于在向量数据库中搜索与输入图像最相似的图像,然后显示搜索结果。
预搜索管道 p_search_pre 使用 p_embed 管道生成 查询图片 的嵌入向量 vec。
# Search pipeline
p_search_pre = (
p_embed.map('vec', ('search_res'), ops.local.search_tcvdb_client(
host=HOST, port=PORT, key=PASSWORD, username=USERNAME,
collectionName=COLLECTION_NAME, dbName=DB_NAME))
.map('search_res', 'pred', lambda x: [str(Path(y[0]).resolve()) for y in x])
)
p_search = p_search_pre.output('img_path', 'pred')
# Search for example query image(s)
dc = p_search('test/goldfish/*.JPEG')
DataCollection(dc).show()
然后对每个元素应用一个 lambda 函数,将每个元素转换为一个文件路径,并将结果存储在 pred 中。
调用 ops.local.search_tcvdb_client 函数连接向量数据库,并搜索与 vec 最相似的向量,将搜索结果存储在 search_res 中。
class SearchTcvdbClient(PyOperator):
def __call__(self, query: 'ndarray'):
tcvdb_result = self.query_data(
query,
**self.kwargs
)
result = []
for hit in tcvdb_result[0]:
row = []
row.extend([hit["path"], hit["score"]])
result.append(row)
return result
def query_data(self, query: [], **kwargs):
# 获取 Collection 对象
db = self._client.database(self.db_name)
coll = db.collection(self.collectionName)
vector = query
if isinstance(query, np.ndarray):
# Convert ndarray to list and float32 to float
vector = list(map(float, query))
# search 提供按照 vector 搜索的能力
# 批量相似性查询,根据指定的多个向量查找多个 Top K 个相似性结果
res = coll.search(
vectors=[vector], # 指定检索向量,
retrieve_vector=False, # 是否需要返回向量字段,False:不返回,True:返回
limit=10, # 指定 Top K 的 K 值
)
return res
搜索管道 p_search 的输出是:
img_path:查询图片的路径。pred:查询到的相似图片路径列表。
使用 p_search 管道对图片 test/goldfish/*.JPEG 的相似图进行搜索。用 Towhee 的 DataCollection 组件显示搜索结果。
+-----------------------------------+------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| img_path | pred |
+===================================+=============================================================================================================================================================================================================================================================================================================================+
| test/goldfish/n01443537_3883.JPEG | [/root/image-search/reverse_image_search/train/goldfish/n01443537_1903.JPEG,/root/image-search/reverse_image_search/train/goldfish/n01443537_2819.JPEG,/root/image-search/reverse_image_search/train/goldfish/n01443537_1415.JPEG,/root/image-search/reverse_image_search/train/goldfish/n01443537_7751.JPEG,...] len=10 |
+-----------------------------------+----------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
DataCollection.show() 函数在显示大量数据时,为了防止在屏幕上显示过多的数据,会省略部分数据。
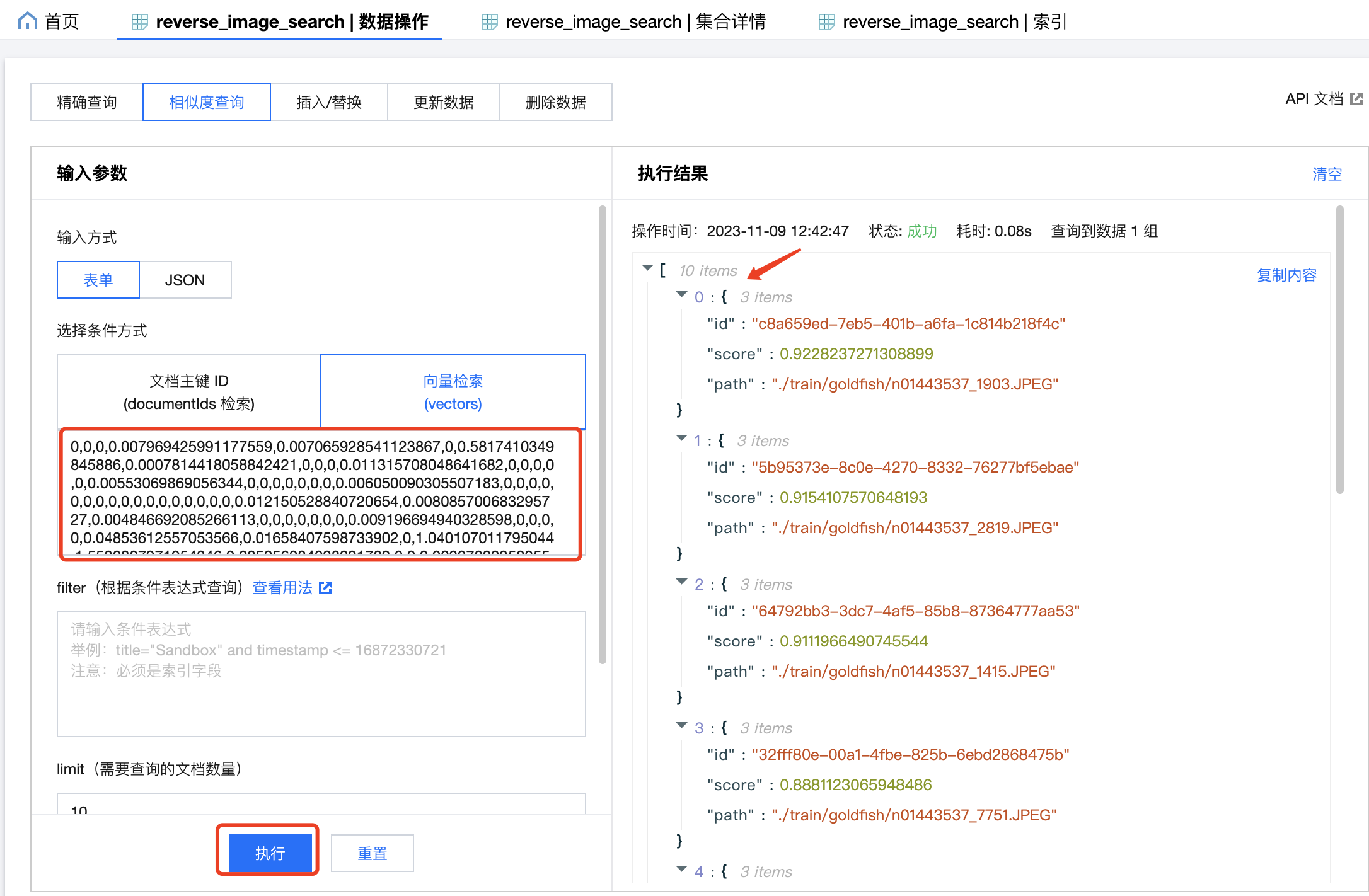
同样的,如果知道了一张图片的向量,可以在 DMC 中用向量检索相似的图片信息,查询到的结果默认按照 score 由高到低排序,越大表示相似度越高。
集成 Gradio#
觉得上述示例中的代码演示对于非技术用户来说不够友好?
我们可以使用 Gradio 提供的 Web UI,以更直观、更互动的方式来展示上述的查询和结果。几秒钟内就可以将上述工作流程以 Web UI 的形式呈现出来。这样,用户可以直接通过上传图片来进行搜索,在界面上展示出相似的图片。
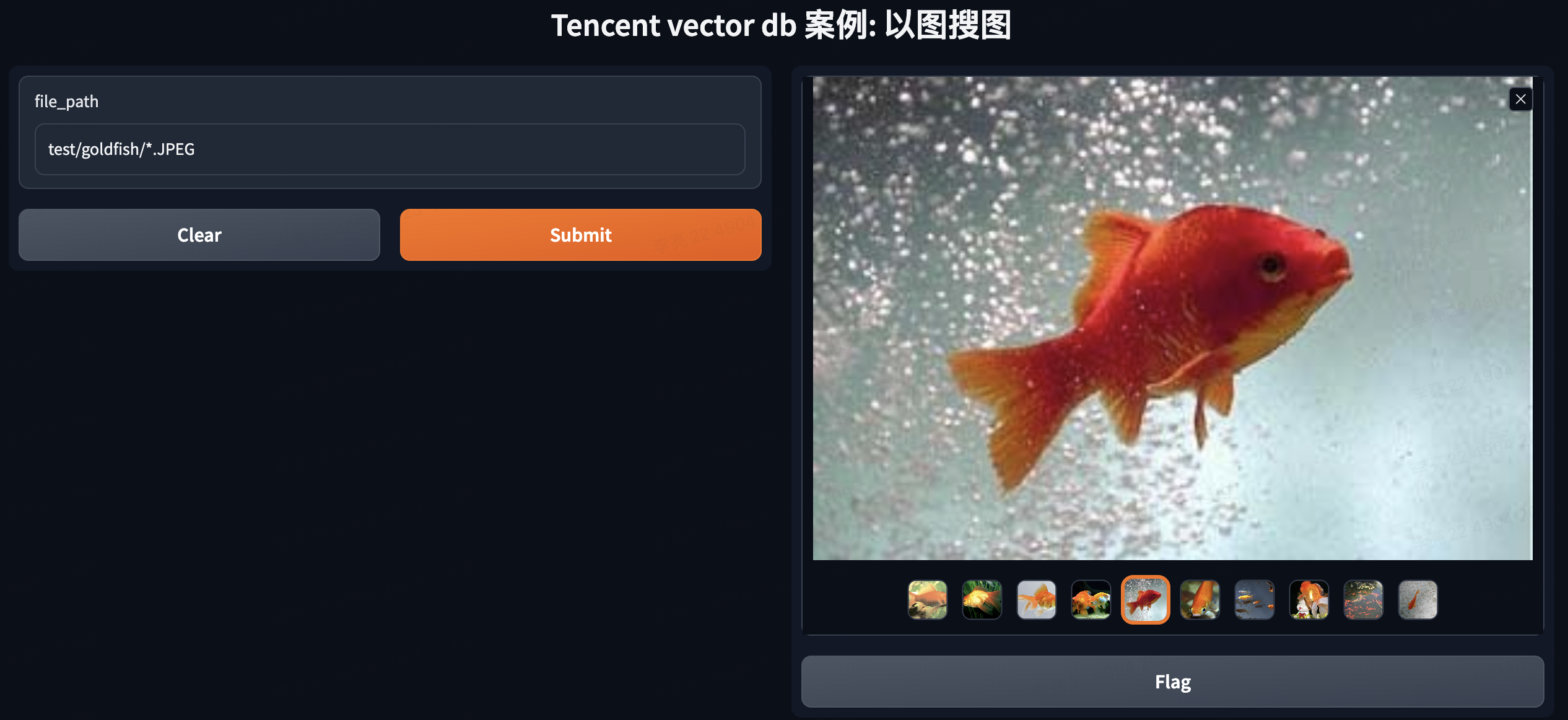
出于演示目的,下面将通过输入图片路径,查询并展示相似的图片。
def search_and_show_images(file_path):
# 使用 `file_path` 进行搜索,返回结果的路径
results = p_search(file_path)
# 从 'DataQueue' 对象中获取数据
data = results.get()
# 获取结果列表
pred = data[1]
return pred
iface = gr.Interface(
fn=search_and_show_images,
# inputs=gr.inputs.File(type="file"),
inputs=gr.inputs.Textbox(default='test/goldfish/*.JPEG'),
outputs=gr.Gallery(label="最终的结果图片").style(height='auto', columns=4),
---
title='Tencent vector db 案例: 以图搜图',
)
iface.launch()
search_and_show_images 会返回类似下面的数据,最终这些图片路径会被展示到 Web UI 上。
[
'/root/image-search/reverse_image_search/train/cuirass/n03146219_11082.JPEG',
'/root/image-search/reverse_image_search/train/loudspeaker/n03691459_40992.JPEG'
]
启动项目。用浏览器打开 http://127.0.0.1:7860 即可看到成果。
输入:test/goldfish/*.JPEG 返回的结果都包含鱼。
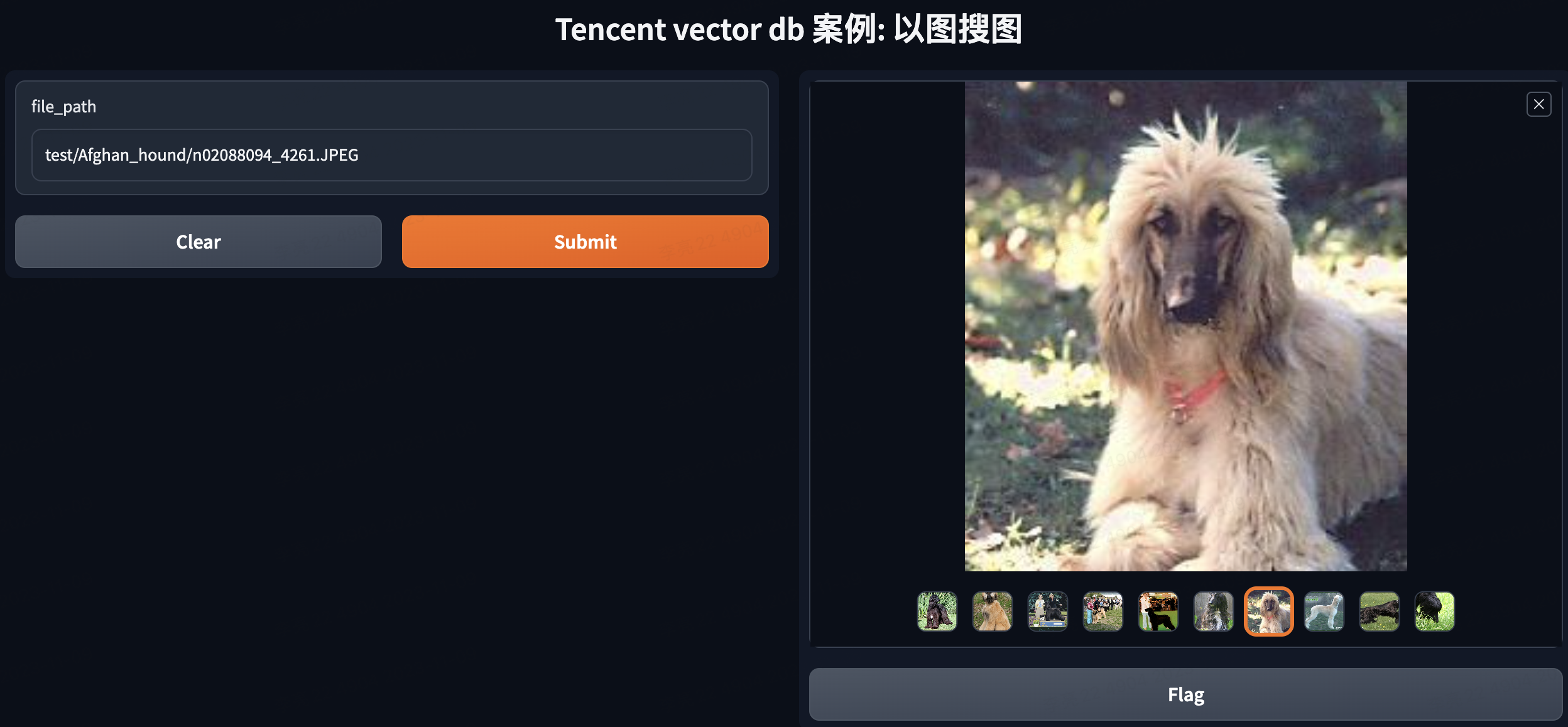
输入:test/Afghan_hound/n02088094_4261.JPEG 返回的结果都包含狗。
总结#
对于构建以图搜图、文字搜视频、私域对话机器人等系统,腾讯云向量数据库由于其卓越的稳定性、性能、易用性和便捷的运维,都展现出了显著优势。得益于大厂的背书,腾讯云向量数据库在 AI 领域中已经成为了领军者。
演示代码地址:https://github.com/smallersoup/image-search