
前两天我们写了单任务版爬虫爬取了珍爱网用户信息,那么它的性能如何呢?
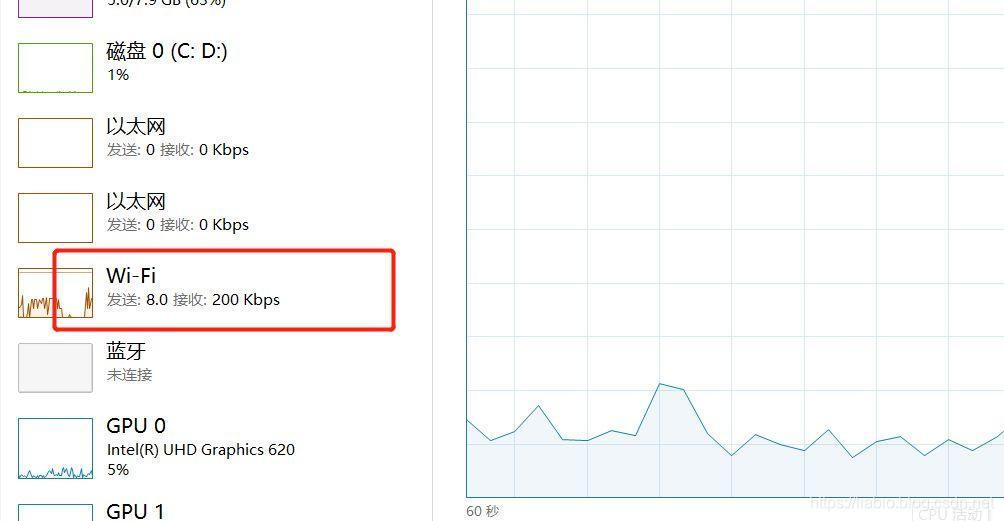
我们可以通过网络利用率看一下,我们用任务管理器中的性能分析窗口可以看到下载速率大概是保持在了200kbps左右,这可以说是相当慢了。
我们针对来通过分析单任务版爬虫的设计来看下:
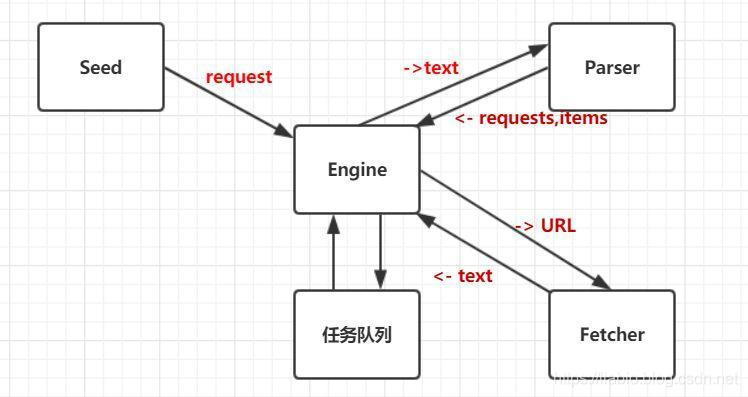
从上图我们可以看出,engine将request从任务队列取出来,送到Fetcher取获取资源,等待数据返回,然后将返回的数据送到Parser去解析,等待其返回,把返回的request再加到任务队列里,同时把item打印出来。
慢就慢在了没有充分利用网络资源,其实我们可以同时发送多个Fetcher和Pareser,等待其返回的同时,可以去做其他的处理。这一点利用go的并发语法糖很容易实现。
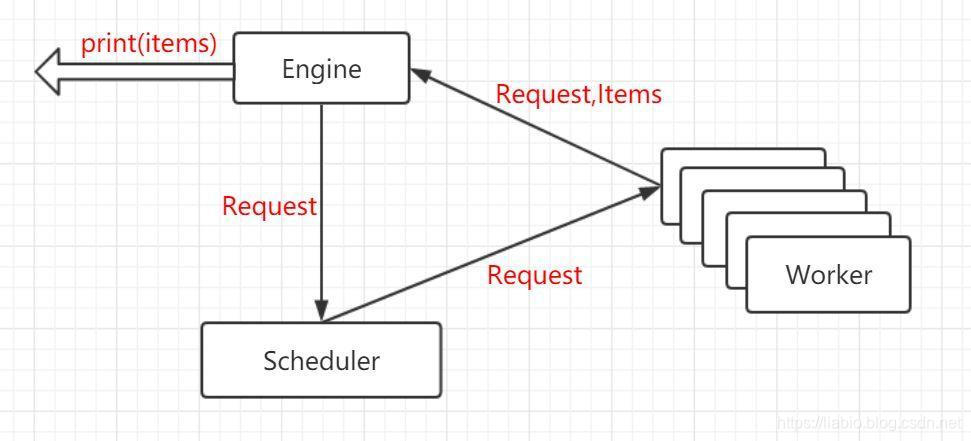
上图中,Worker是Fetcher和Parser的合并,Scheduler将很多Request分发到不同的Worker,Worker将Request和Items返回到Engine,Items打印出来,再把Request放到调度器里。
基于此用代码实现:
Engine:
package engine
import (
"log"
)
type ConcurrentEngine struct {
Scheduler Scheduler
WokerCount int
}
type Scheduler interface {
Submit(Request)
ConfigureMasterWorkerChan(chan Request)
}
func (e *ConcurrentEngine) Run(seeds ...Request) {
in := make(chan Request)
out := make(chan ParserResult)
e.Scheduler.ConfigureMasterWorkerChan(in)
//创建Worker
for i := 0; i < e.WokerCount; i {
createWorker(in, out)
}
//任务分发给Worker
for _, r := range seeds {
e.Scheduler.Submit(r)
}
for {
//打印out的items
result := <- out
for _, item := range result.Items {
log.Printf("Get Items: %v\n", item)
}
//将out里的Request送给Scheduler
for _, r := range result.Requests {
e.Scheduler.Submit(r)
}
}
}
//workerConut goroutine to exec worker for Loop
func createWorker(in chan Request, out chan ParserResult) {
go func() {
for {
request := <-in
parserResult, err := worker(request)
//发生了错误继续下一个
if err != nil {
continue
}
//将parserResult送出
out <- parserResult
}
}()
}
Scheduler:
package scheduler
import "crawler/engine"
//SimpleScheduler one workChan to multi worker
type SimpleScheduler struct {
workChan chan engine.Request
}
func (s *SimpleScheduler) ConfigureMasterWorkerChan(r chan engine.Request) {
s.workChan = r
}
func (s *SimpleScheduler) Submit(r engine.Request) {
go func() { s.workChan <- r }()
}
Worker:
func worker(r Request) (ParserResult, error) {
log.Printf("fetching url:%s\n", r.Url)
//爬取数据
body, err := fetcher.Fetch(r.Url)
if err != nil {
log.Printf("fetch url: %s; err: %v\n", r.Url, err)
//发生错误继续爬取下一个url
return ParserResult{}, err
}
//解析爬取到的结果
return r.ParserFunc(body), nil
}
main函数:
package main
import (
"crawler/engine"
"crawler/zhenai/parser"
"crawler/scheduler"
)
func main() {
e := &engine.ConcurrentEngine{
Scheduler: &scheduler.SimpleScheduler{},
WokerCount :100,
}
e.Run(
engine.Request{
Url: "http://www.zhenai.com/zhenghun",
ParserFunc: parser.ParseCityList,
})
}
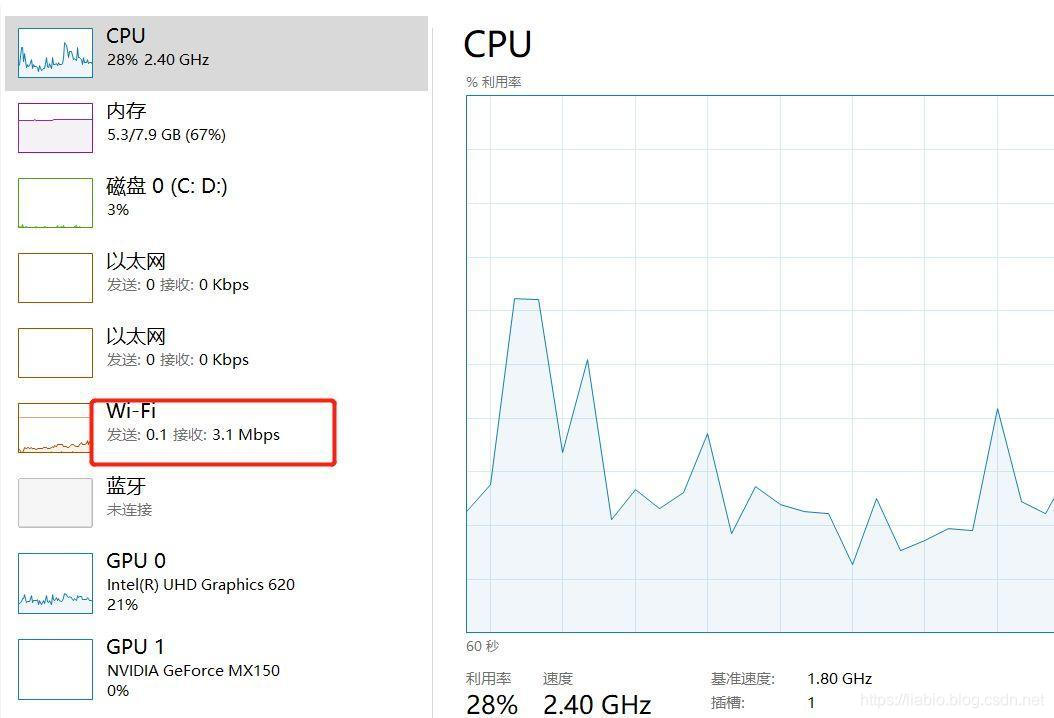
这里开启100个Worker,运行后再次查看网络利用率,变为3M以上。
由于代码篇幅较长,需要的同学可以关注公众号回复:go爬虫 获取。