
Build an Image Search System in 5 Minutes#
Vectors and Vector Databases#
In mathematics, a vector is an object that can represent multiple dimensions or characteristics. In our daily life, it can also be used to describe multiple attributes of an object.
For example, to describe an apple, we need to focus on its features (like variety), origin, color, size, and sweetness. We can treat these attributes as multiple dimensions of the apple and then represent the apple with a vector.
For instance, if we define each element of the vector to represent:
- Feature (e.g., 1 for Fuji apple, 2 for Granny Smith)
- Origin (e.g., 1 for Luochuan, 2 for Yantai)
- Color (e.g., 1 for red, 2 for green)
- Size (based on actual weight, e.g., 150 means the apple weighs 150 grams, 200 means 200 grams)
- Sweetness (e.g., 1 for very sweet, 0.5 for average, 0 for not sweet)
Then a Fuji apple from Yantai, red in color, weighing 150 grams, and with sweetness 0.8, can be represented by the vector [1, 2, 1, 150, 0.8]. This vector comprehensively describes all the attributes of the apple.
This is the concept of vectors. In artificial intelligence and machine learning, we can vectorize and store complex data types such as audio, images, and text. Traditional databases are primarily designed for handling structured data, but they are inefficient when processing complex data types.
In contrast, vector databases support multiple types of indexes and similarity computation methods, efficiently storing and querying large-scale vector data.
Applications of Vector Databases#
Imagine one day you eat a delicious dish at a restaurant but don’t know its name or how to make it. You could take a photo of the dish and use an image search feature to find similar dishes and their recipes online.
Consider an online recipe platform that stores numerous dish images and corresponding recipes. Each dish image has its features extracted and stored as an embedding vector in a vector database.
When the user uploads a photo of a dish for searching, the platform first extracts features from the photo to generate an embedding vector, then searches for the most similar dish images in the vector database.
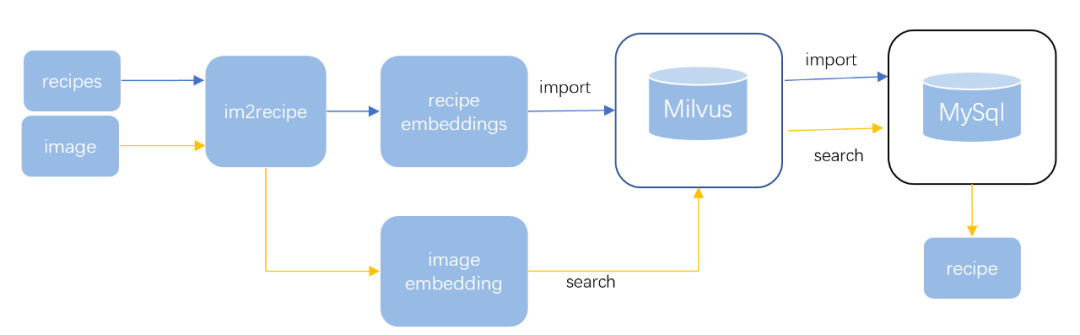
The search results return similar dish images along with their recipes. Users can browse these recipes to find the dish they want to make.
This image search feature helps users find the recipes they like and discover new dishes they might enjoy. For the recipe platform, it’s an effective way to attract and retain users.
Additionally, image search technology has many practical applications in daily life, such as recommending similar products or assisting law enforcement in recognizing faces in surveillance videos to improve crime-solving efficiency.
All these applications require a high-performance vector database. In this article, we will build an image search system to experience the entire workflow firsthand.
Tencent Cloud Vector Database#
The Tencent Cloud Vector Database offers powerful capabilities for storing, retrieving, and analyzing large amounts of multi-dimensional vector data, supporting up to 1 billion single-index vectors, millions of QPS, and millisecond-level query latency. Currently, it serves thousands of customers stably, and we can create a vector database instance within minutes.
Testing Version: Single availability zone, single node.
The entire creation process takes about 1-2 minutes. Refresh the instance list to see the created instance.

Retrieve the password for username root from the key management, which will be used later:

Enable external access: You can use the system-assigned domain name and port to access the vector database externally:
It takes about 10 seconds to take effect. Note down the generated domain (HOST) and port (PORT).
Configure the whitelist: For testing purposes, the whitelist IP range can be set to 0.0.0.0/0, meaning open to all IPs.
Test external connectivity with the following command:
curl -i -X POST \
-H 'Content-Type: application/json' \
-H 'Authorization: Bearer account=root&api_key=A5VOgsMpGWJhUI0WmUbY********************' \
http://10.0.X.X:80/database/create \
-d '{
"database": "db-test"
}'
It returns the result as follows. If it fails to connect or times out, the whitelist configuration is incorrect.
{"code":0,"msg":"operation success","affectedCount":1}
Image Search Example#
We will use Towhee and Tencent Cloud Vector Database to build a reverse image search system.
Towhee is an open-source framework for building powerful data pipelines. It can efficiently handle various data transformation tasks.
This system takes an image as input and retrieves the most similar images based on the content of the image. The basic idea is to use a pre-trained deep learning model to extract the features from each image and represent it as an embedding vector. Then, by storing and comparing these image embedding vectors, we can implement image retrieval.
The workflow is as follows:
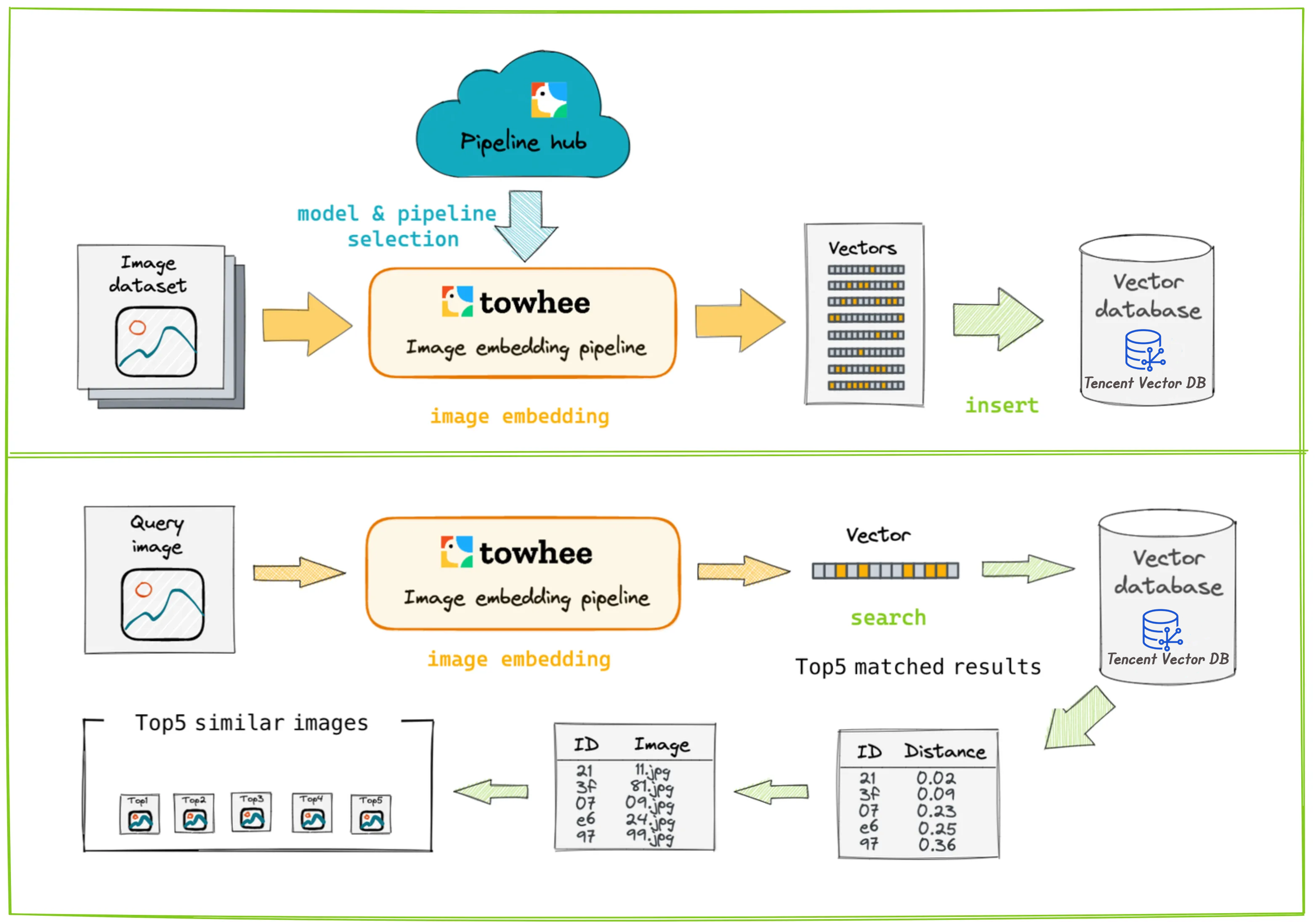
First, use Towhee to preprocess the input image and extract features to obtain the image embedding vector. Then, store this embedding vector into the vector database. When an image needs to be queried, preprocess and extract features from the query image to get the query image embedding vector. Perform similarity search in the vector database using this vector, and the vector database will return the top k similar vectors.
Create Project#
We will explain the important code parts below. The final demo code, which is available at the end of the article, can be run locally. This is very friendly for beginners.
- Create a new project directory:
mkdir -p image-search
cd image-search
- Create a new Python virtual environment (optional but recommended):
$ python -V
Python 3.9.0
$ python -m venv venv
Creating a new Python virtual environment can effectively isolate project dependencies and simplify dependency management.
Activate the virtual environment:
- Linux/macOS:
source venv/bin/activate
- Windows:
.\venv\Scripts\activate
- Install the required Python packages:
python -m pip install -q towhee opencv-python pillow tcvectordb
This command will install the Towhee, OpenCV, Pillow, and tcvectordb libraries into the virtual environment venv.
Prepare Data#
Here, we use a subset of the ImageNet dataset (100 categories). Sample data can be obtained on GitHub.
curl -L https://github.com/towhee-io/examples/releases/download/data/reverse_image_search.zip -O
unzip -q -o reverse_image_search.zip
The ImageNet dataset is a large-scale visual dataset widely used in deep learning for image classification and object detection tasks. In this article, we use a subset of ImageNet, which provides a suitable scale and complexity for model training and validation.
The directory structure is as follows:
train: Contains candidate images, with 100 different categories, each category containing 10 images.test: Contains query images, with the same 100 categories as the training set, but each category has only 1 image.reverse_image_search.csv: A CSV file containing the id, path, and labels of each training image.
Candidate imagesare the images that can be retrieved, andquery imagesare the images used for retrieval.
Connect to Database and Create Collection#
Connecting to Tencent Vector DB is straightforward. The official SDK supports multiple languages. In this article, we use the Python SDK: tcvectordb to operate the vector database.
First, use the tcvectordb SDK to write the client code for connecting to the vector database:
class TcvdbClient(PyOperator):
def __init__(self, host: str, port: str, username: str, key: str, dbName: str, collectionName: str, timeout: int = 20):
# Initialize client
"""
self.collectionName = collectionName
self.db_name = dbName
self._client = tcvectordb.VectorDBClient(url="http://" + host + ":" + port, username=username, key=key, read_consistency=ReadConsistency.EVENTUAL_CONSISTENCY, timeout=timeout)
Then, call TcvdbClient to create the client:
# tcvdb parameters
HOST = 'lb-xxxx.clb.ap-beijing.tencentclb.com'
PORT = '10000'
DB_NAME = 'image-search'
COLLECTION_NAME = 'reverse_image_search'
PASSWORD = 'xxxx'
USERNAME = 'root'
# path to csv (column_1 indicates image path) OR a pattern of image paths
INSERT_SRC = 'reverse_image_search.csv'
test_vdb = TcvdbClient(host=HOST, port=PORT, key='6qlvBkF0xAgZoN7VJbcwLCqrxoSS4J63Q7mu4RgF', username='root', collectionName=COLLECTION_NAME, dbName=DB_NAME)
The HOST, PORT, USERNAME, and PASSWORD above are obtained after applying for the vector database.
Create DB and Collection in the vector database:
class TcvdbClient(PyOperator): def create_db_and_collection(self):
database = self.db_name
coll_embedding_name = self.collectionName
coll_alias = self.collectionName + "-alias"
# Create DB
db = self._client.create_database(database)
# Build Collection
index = Index()
index.add(VectorIndex('vector', 2048, IndexType.HNSW, MetricType.COSINE, HNSWParams(m=16, efconstruction=200)))
index.add(FilterIndex('id', FieldType.String, IndexType.PRIMARY_KEY))
index.add(FilterIndex('path', FieldType.String, IndexType.FILTER))
# Create Collection
db.create_collection( name=coll_embedding_name, shard=3, replicas=0, description='image embedding collection', index=index, embedding=None, timeout=20 )
test_vdb.create_db_and_collection()
The above code creates a Collection with three indexes. In a vector database, Collection is the primary structure for storing and retrieving vectors. Creating index fields can be used as filtering in retrieval.
vector: The index has2048vector dimensions. The more dimensions, the more information the vector can represent, but it also increases computational complexity and storage requirements.IndexType.HNSW: The type of index. This is an approximate nearest neighbor search algorithm to accelerate high-dimensional vector search.MetricType.COSINE: Cosine similarity, which measures the angle between two vectors and is commonly used to measure high-dimensional vector similarity.id: The primary key index, used to uniquely identify each vector.path: The filter index to accelerate queries based on thepathfield.
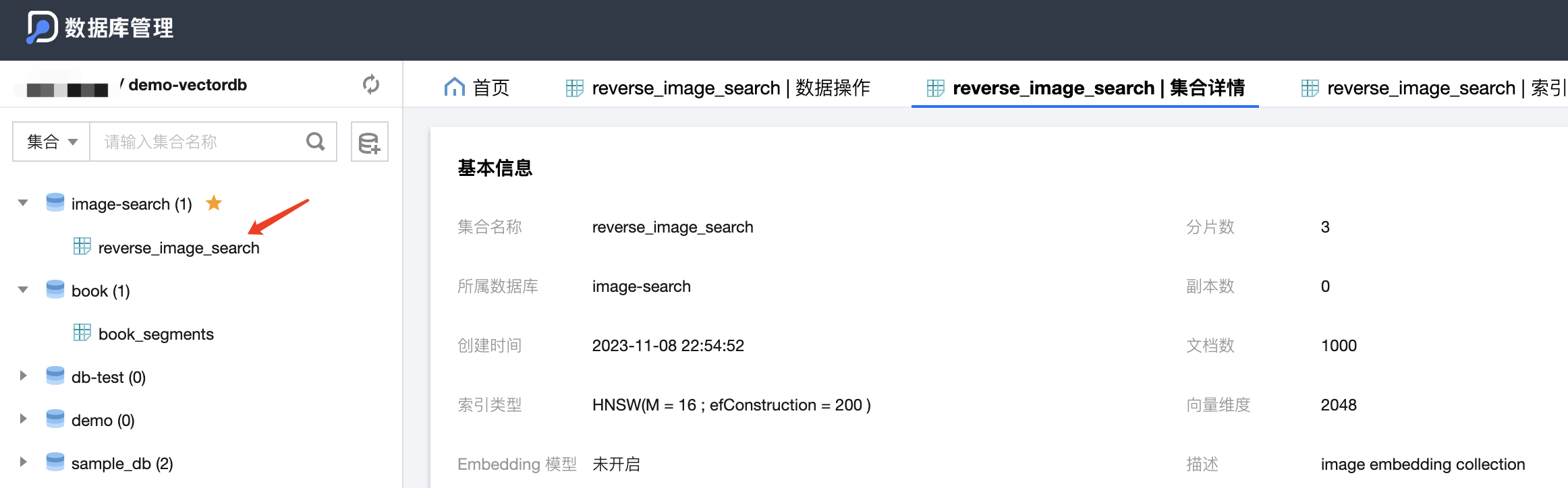
After creation, you can conveniently view and manage the vector database data through the Database Management Console (DMC):
DMC access link: https://dms.cloud.tencent.com/
Here is the newly created DB and Collection:
Embedding: Image to Vector, Insert into Database#
In machine learning, embedding is the process of converting raw input data such as text, images, and audio into a form more suitable for machine learning, i.e., converting complex data structures (like images or text) into fixed-length vectors.
Below, we use Towhee’s pipeline to implement image feature extraction and vector storage:
MODEL = 'resnet50'
DEVICE = None # if None, use default device (cuda is enabled if available)
INSERT_SRC = 'reverse_image_search.csv'
# Embedding pipeline
p_embed = (
pipe.input('src')
.flat_map('src', 'img_path', load_image)
.map('img_path', 'img', ops.image_decode())
.map('img', 'vec', ops.image_embedding.timm(model_name=MODEL, device=DEVICE))
)
# Display embedding result, no need for implementation
p_display = p_embed.output('img_path', 'img', 'vec')
DataCollection(p_display('./test/goldfish/*.JPEG')).show()
# Insert pipeline
p_insert = (
p_embed.map(('img_path', 'vec'), 'mr', ops.local.tcvdb_client(
host=HOST, port=PORT, key=PASSWORD, username=USERNAME,
collectionName=COLLECTION_NAME, dbName=DB_NAME
))
.output('mr')
)
# Insert data
p_insert(INSERT_SRC)
The Embedding Pipeline defines a pipeline p_embed that loads the images in reverse_image_search.csv, calls ops.image_embedding.timm(), and uses the resnet50 model to convert the image data into embedding vectors.
Towhee provides a pre-trained ResNet50 model that can convert images into vectors. ResNet50 is a deep convolutional neural network that performs well in many image recognition tasks. This model learns important features of images and embeds these features into a high-dimensional vector referred to as an embedding vector.
The Display Pipeline defines a pipeline p_display used to display the results of p_embed.
The Insert Pipeline defines a pipeline p_insert to insert the embedding vectors into the vector database.
p_insert(INSERT_SRC) uses the p_insert pipeline to handle the image data in the reverse_image_search.csv file.
Ultimately, it calls ops.local.search_tcvdb_client to insert the generated vectors into the vector database:
def __call__(self, *data):
path = ""
vector = []
for item in data:
if isinstance(item, np.ndarray):
# Convert ndarray to list and float32 to float
vector = list(map(float, item))
else:
path = item
# Generate a random UUID and convert to string
document_list = [
Document(
id=str(uuid.uuid4()),
path=path,
vector=vector),
]
db = self._client.database(self.db_name)
coll = db.collection(self.collectionName)
coll.upsert(documents=document_list)
You can use the fields with indexes created before to filter and accurately query the inserted data in DMC, for example, search: path="./train/goldfish/n01443537_1903.JPEG":
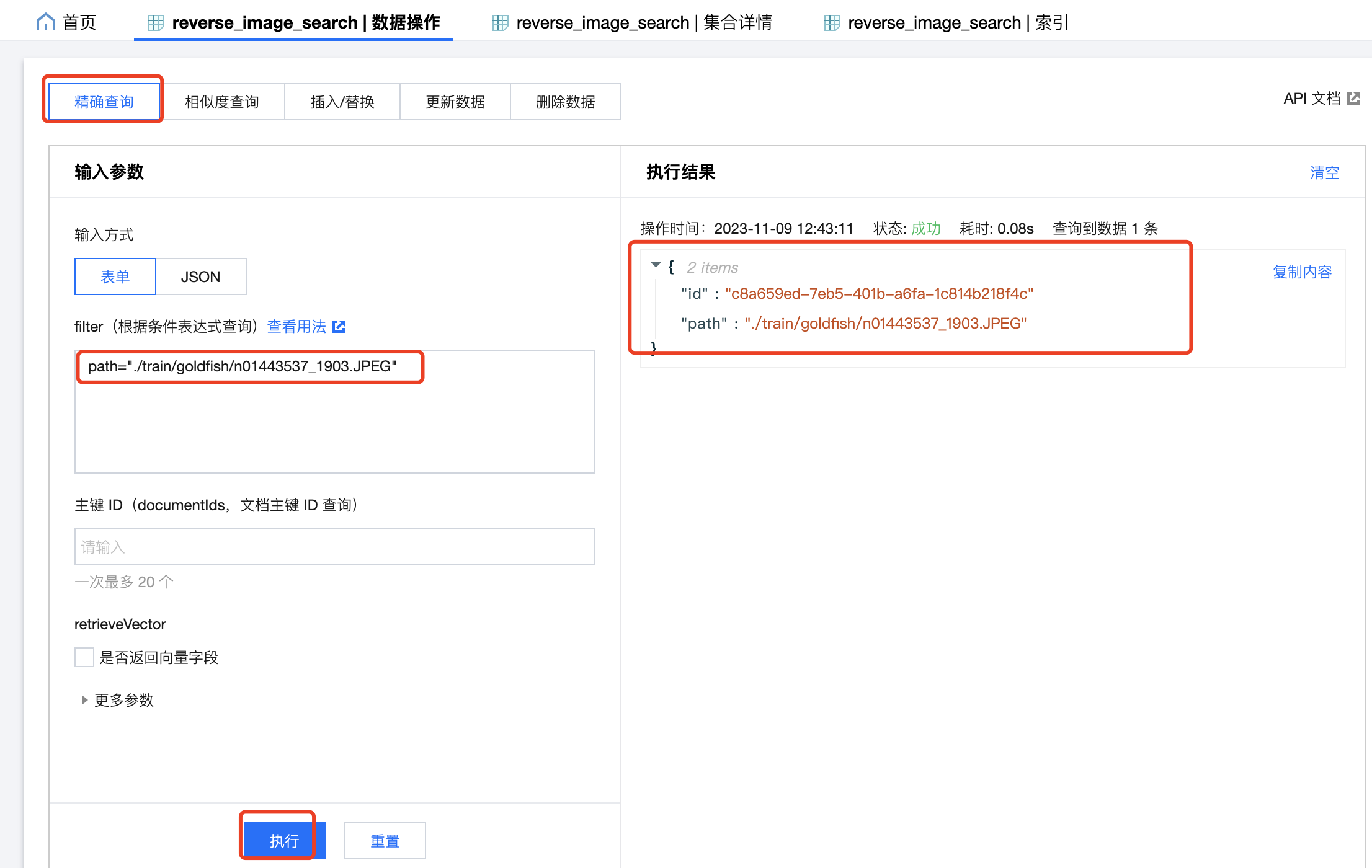
Since vector data is generally large, it will not be returned by default. If you need to return the vector field, check retrieveVector.
Search Similar Images#
Define a search pipeline p_search to search for images most similar to the input image in the vector database, then display the search results.
The pre-search pipeline p_search_pre uses the p_embed pipeline to generate the embedding vector vec for the query image.
# Search pipeline
p_search_pre = (
p_embed.map('vec', ('search_res'), ops.local.search_tcvdb_client(
host=HOST, port=PORT, key=PASSWORD, username=USERNAME,
collectionName=COLLECTION_NAME, dbName=DB_NAME))
.map('search_res', 'pred', lambda x: [str(Path(y[0]).resolve()) for y in x])
)
p_search = p_search_pre.output('img_path', 'pred')
# Search for example query image(s)
dc = p_search('test/goldfish/*.JPEG')
DataCollection(dc).show()
Then apply a lambda function to each element to convert each element to a file path and store the result in pred.
Call the ops.local.search_tcvdb_client function to connect to the vector database and search for the vectors most similar to vec, storing the search results in search_res.
class SearchTcvdbClient(PyOperator):
def __call__(self, query: 'ndarray'):
tcvdb_result = self.query_data(
query,
**self.kwargs
)
result = []
for hit in tcvdb_result[0]:
row = []
row.extend([hit["path"], hit["score"]])
result.append(row)
return result
def query_data(self, query: [], **kwargs):
# Obtain Collection object
db = self._client.database(self.db_name)
coll = db.collection(self.collectionName)
vector = query
if isinstance(query, np.ndarray):
# Convert ndarray to list and float32 to float
vector = list(map(float, query))
# search provides the ability to search by vector
# Batch similarity query, find multiple Top K similar results based on specified multiple vectors
res = coll.search(
vectors=[vector], # Specify search vector
retrieve_vector=False, # Whether to return the vector field, False: do not return, True: return
limit=10, # Specify the K value of Top K
)
return res
Output of the Search Pipeline p_search#
img_path: Path of thequery image.pred: List of paths of similar images found.
We use the p_search pipeline to search for images similar to test/goldfish/*.JPEG. The results are displayed using Towhee’s DataCollection.
+-----------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
| img_path | pred |
+===================================+=========================================================================================================================================================================+
| test/goldfish/n01443537_3883.JPEG | [/root/image-search/reverse_image_search/train/goldfish/n01443537_1903.JPEG,/root/image-search/reverse_image_search/train/goldfish/n01443537_2819.JPEG,...] len=10 |
+-----------------------------------+--------------------------------------------------------------------------------------------------------------------------------------------------------------------------+
The
DataCollection.show()function omits some data when displaying large datasets to prevent overwhelming the screen.
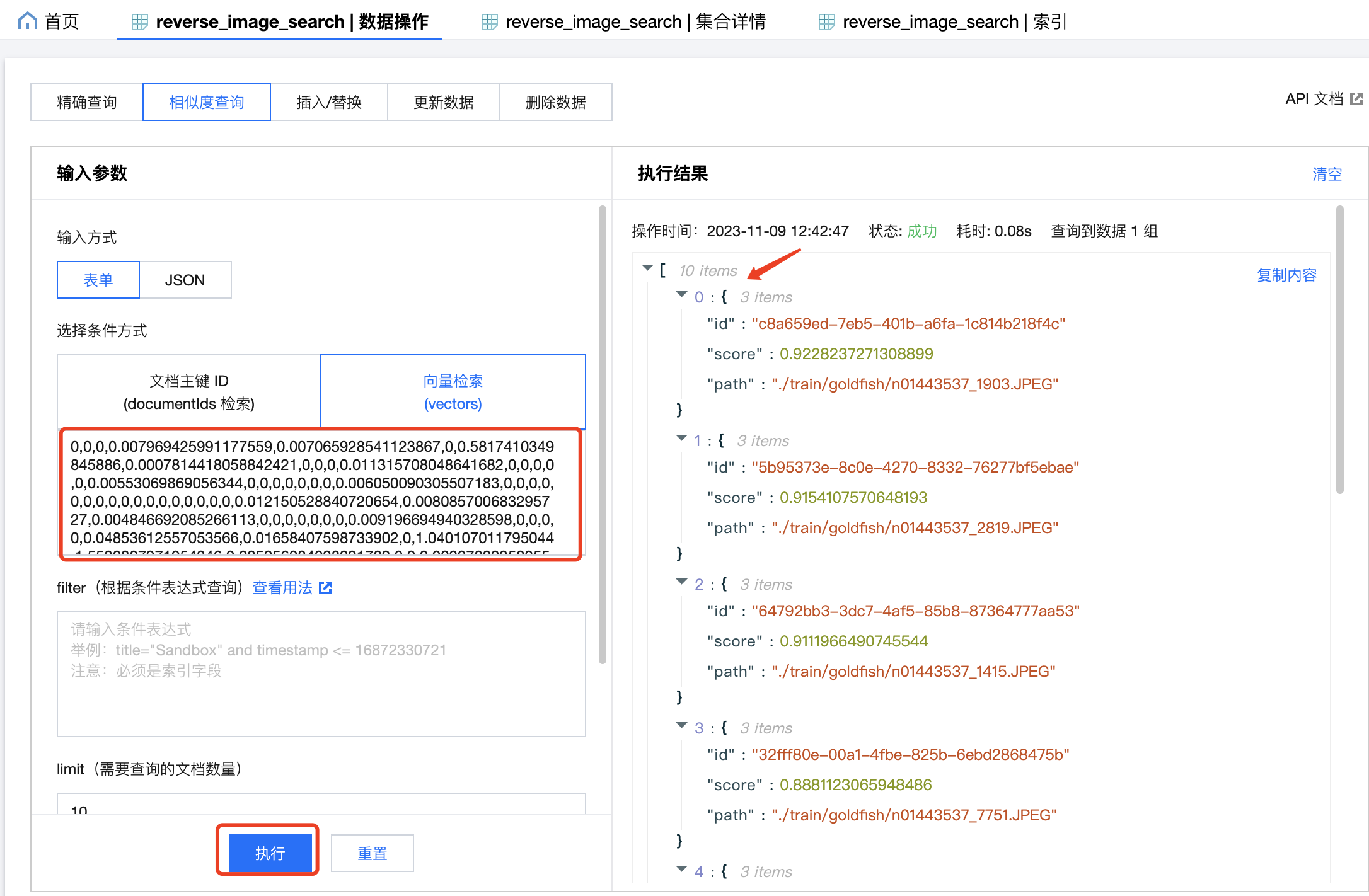
Similarly, if you have the vector of an image, you can use DMC to query information about similar images by vector. The results are sorted by score in descending order, with a higher score indicating higher similarity.
Integrating Gradio#
Feel that the code demonstration above is not friendly enough for non-technical users?
We can use Gradio to provide a web UI to showcase the queries and results more visually and interactively. In just a few seconds, we can present the workflow in a web UI form. This allows users to search by directly uploading images and displaying similar images in the interface.
For demonstration purposes, the following will search and display similar images by inputting image paths.
def search_and_show_images(file_path):
# Use `file_path` for the search and return result paths
results = p_search(file_path)
# Retrieve data from 'DataQueue' object
data = results.get()
# Get result list
pred = data[1]
return pred
iface = gr.Interface(
fn=search_and_show_images,
inputs=gr.inputs.Textbox(default='test/goldfish/*.JPEG'),
outputs=gr.Gallery(label="Result Images").style(height='auto', columns=4),
title='Tencent Vector DB Example: Image Search',
)
iface.launch()
The search_and_show_images function will return data like the following, which eventually displays the image paths in the web UI.
[
'/root/image-search/reverse_image_search/train/cuirass/n03146219_11082.JPEG',
'/root/image-search/reverse_image_search/train/loudspeaker/n03691459_40992.JPEG'
]
Launch the project. Open your browser to http://127.0.0.1:7860 to see the final result.
Input: test/goldfish/*.JPEG returns results containing fish.
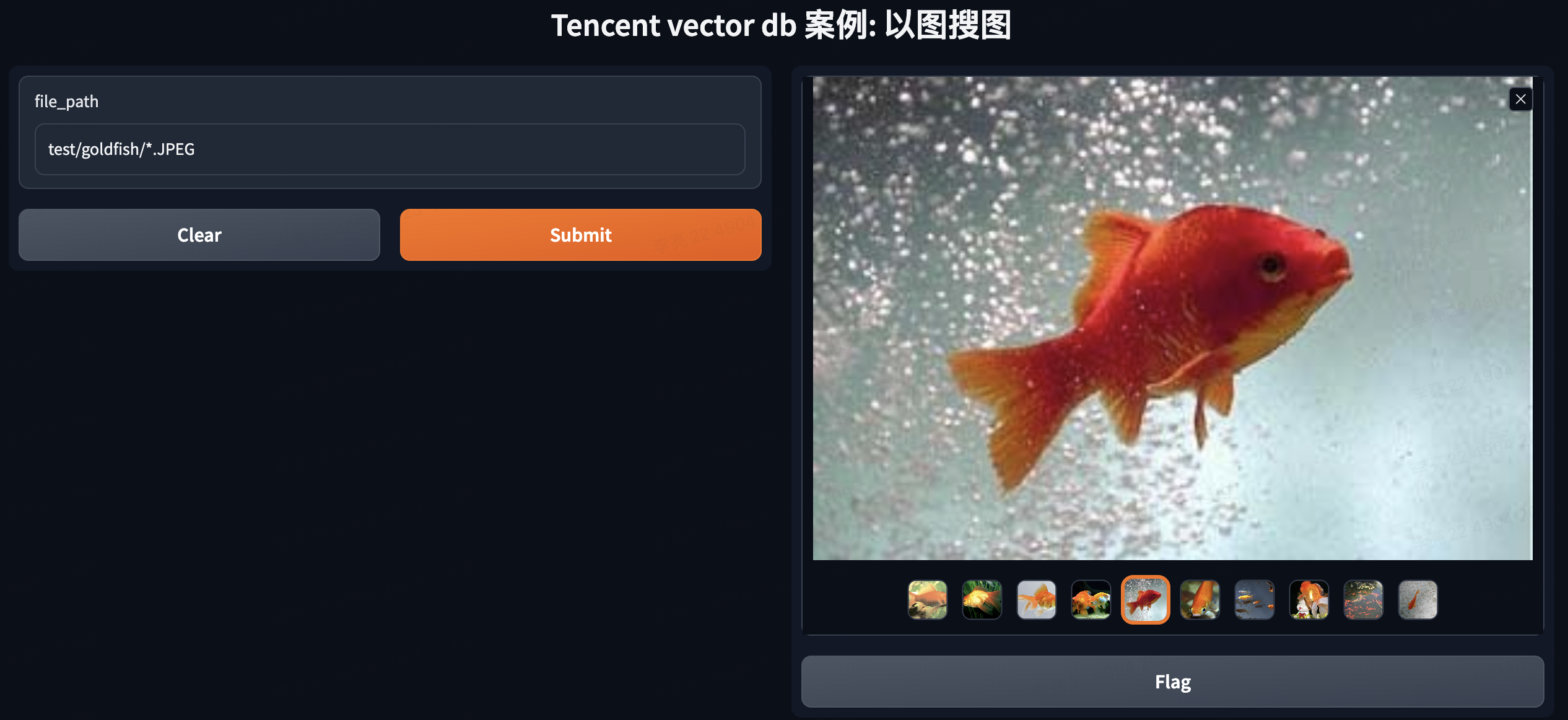
Input: test/Afghan_hound/n02088094_4261.JPEG returns results containing dogs.
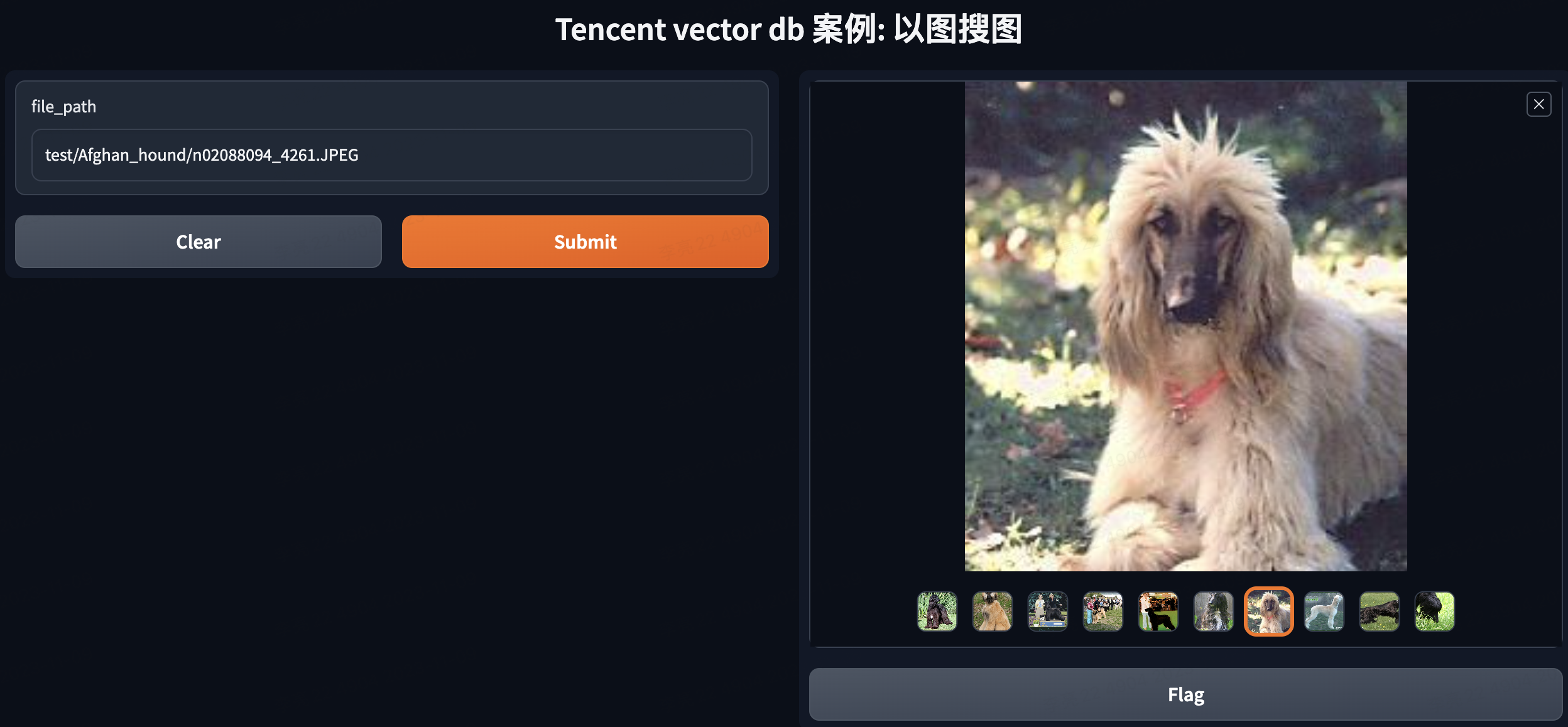
Summary#
For building systems like image search, text-to-video, and private domain chatbots, Tencent Cloud Vector Database demonstrates remarkable advantages due to its excellent stability, performance, ease of use, and convenient maintenance. Backed by a major company, Tencent Cloud Vector Database has become a leader in the AI field.
Demo code available at: https://github.com/smallersoup/image-search